
In order to experiment with cyber threat detection techniques you need lots of data. Fortunately modern networked systems generate huge volumes of events, including packet traces, flow statistics, firewall logs, server logs, audit logs traces, transactions logs and so forth. The real challenge is getting hold of this data with representative captures that include recent threats with realistic distributions.
How to Obtain Representative Event Data
There are several ways in which you can go about obtaining useful data, including:
- Public repositories
- Private repositories
- Reproduce a Live Environment
- Simulation
Public Repositories: The advantage of public sources is that there is a common dataset with which to compare findings with other researchers. These datasets tend to be fairly generic, with a broad range of threat vectors. That said, there are particular challenges with finding fully representative and current data: these datasets may be several years old, the threat landscape changes quickly, and in some cases the overall event composition may be of questionable value (depending on how the original data was generated). Nevertheless these datasets are still valuable places to start, and several have been used widely in comparative studies within the research community.
Private Repositories: Here you will very likley be dealing with real event data from a from a real network. That said, there may be major restrictions on what you have access to, how much of the information you can publish, and how original the data is (it is highly likley to be pseudonymised, addresses and user data may be masked etc.). It is also likley that that data source is specific to a particular type of environment (e.g. retail bank, exchange, healthcare), which might be an advantage depending upon the type of problem you are researching. Threat vectors (at least visible ones) may be restricted to only those available after security controls have done their job - these are typically not the kind of environments where malware is allowed to run wild (unless it is a special restricted part of the network such as a honeypot).
Reproduce a Live Environment: By generating and capturing the events yourself (assuming you can also generate real attack traffic using a sandboxed malware environment) you can get live working data. From a pure event perspective this data is 'accurate'. The downsides are that the environment may be relatively small, laborious to setup and reproduce, and the potential attack vectors are limited to those you can find and execute. It can also be impossible to faithfully reproduce this environment, and the relative mixes of normal and anomalous traffic is open to question. This can however be a useful way to examine fine grained models of particular threat vectors (such as profiling flow asymmetry and burstiness where published data is not available). That said, this method has also been used in major initiatives to record complete trace libraries for public use. The logistics of setting up large scale environments however means that these datasets start to become stale quite quickly.
Simulation: Simulation has some major advantages, enabling you to generate huge event volumes, with a very large simulated network. You can also vary threat levels and types easily - enabling testing of different mixes of normal and anomalous behaviour, with different time intervals. You can also generate threat vectors that are not yet publicly known. The downsides are that simulation models can be completely wrong. Simulators may output results with superficially impressive precision, giving confidence in a particular model. Building a simulated model can be non trivial without expert domain knowledge. In order to combat this you will need to to validate models against representative data (such as a public data set or live environment), ideally reviewed by a domain expert. That said, in many cases simulation
In practice it's worthwhile considering a hybrid approach, using at least one public source to validate against. It's also worth noting that some of the public datasets are themselves partially or wholly simulated. In my own research I have used discrete event packet flow simulation models and validated these against well known event sources to approximate normal and anomalous traffic distributions and timings at realistic scale. For protocol based data this means modelling packet flows down to the byte count distribution, level of asymetry, entropy, and other factors.
Public Event Sources
Below is a list of public event sources that can be used for modelling and analysing cyber security threats and anomalous behaviour. Note that these are organised by date, most recent first. It should be clear that many of these datasets, including several of the most widely cited, are long out of date. In cybersecurity we really need to be looking at recent attacks as well as legacy vectors. Obtaining representative, accurate and useful training material is notoriously difficult challenge in this field, and despite the obvious value of many of these datasets when published, keeping them up to date proves extremely difficult.
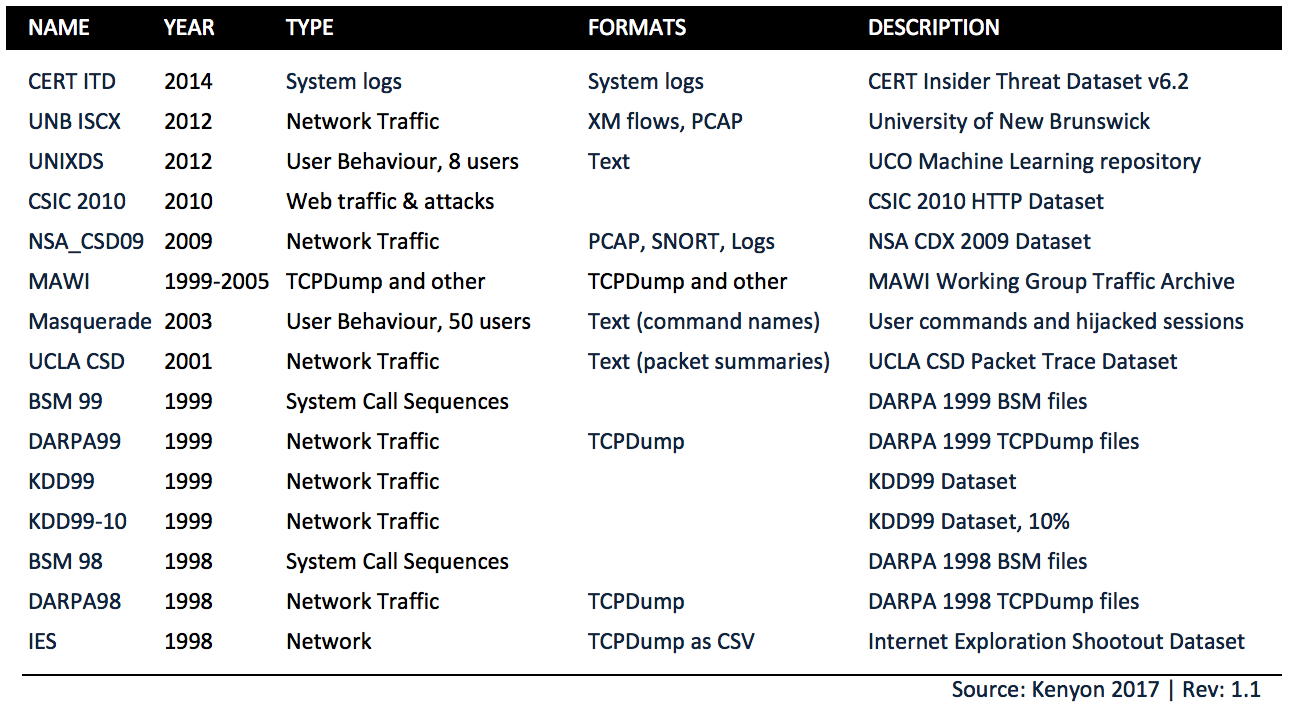
Unsurprisingly (and paradoxically) most organisations that have the scale and capability to offer really useful data, and would benefit the most from advances in research, are highly protective of such information; not least because publishing such information has the potential to expose infrastructure vulnerabilities, as well as exposing potentially sensitive information. The effort to pseudonimise such data can be prohibitive, and without careful masking a potential attacker can still obtain useful information through statistical analysis.
Some of the more recent datasets (such as UNB ISCX2012) can provide valuable insight into threat modelling and discovery, but their use needs to be carefully orchestrated and considered against the use case. Perhaps the most pragmatic way to view these datasets is as a 'snapshot' of the threat landscape, viewed through a wide angled lense.
You can find more details on publicly available datasets here.
Simulated Event Sources
Another option that used widely is simulation; this offers a great deal of flexibility but any such model needs carefully architecting and validating to ensure it can generate realistic event distributions and timings. There are a number of commercial tools available with extensive libraries such as:
- OPNET
- QualNet
as well as open source tools, such as:
- NS2
- NS3
- SSFNet
- REAL
- OMNeT++
- J-Sim
- YANS
Which tool you use really depends on the kind of events you are modelling, the level of granularity in modelling required, budget, and the level of support you need. You may want to model something very specific, or test scenarios that are simply not possible in these tools, and this may require custom development.
It should be possible to create standardised simulations that can be refined and calibrated against live environments and public datasets, and gradually build up libraries of sample flow distributions (for example) that can be updated and maintained continuously. These libraries would need to approximately well (statistically) to the sample distributions, mixes and timings in real flows. This is a particular area of interest personally; and I have processed some public datasets into a 'normalised' form within a simulation environment, enabling both simulated and live traffic to be replayed side-by-side. This is possible where there is enough data in the public dataset. For details of related research into large scale protocol flow simulation see my research. Related academic papers and articles can be found here.
